繁體中文手寫字體 - 網頁辨識
你/妳 寫的字,美醜 AI 都知道...
有了初步的數據、進行特徵工程的前處理、架構深度學習模型、反覆訓練出成效理想的模型,最後,相信每個 AI 工程師就是期待自己的作品能夠實際落地應用;因此除了邊緣運算(Edge Computing)外,最能快速提供給使用者最直接、簡單的 AI 服務就是網頁瀏覽。
作品概要
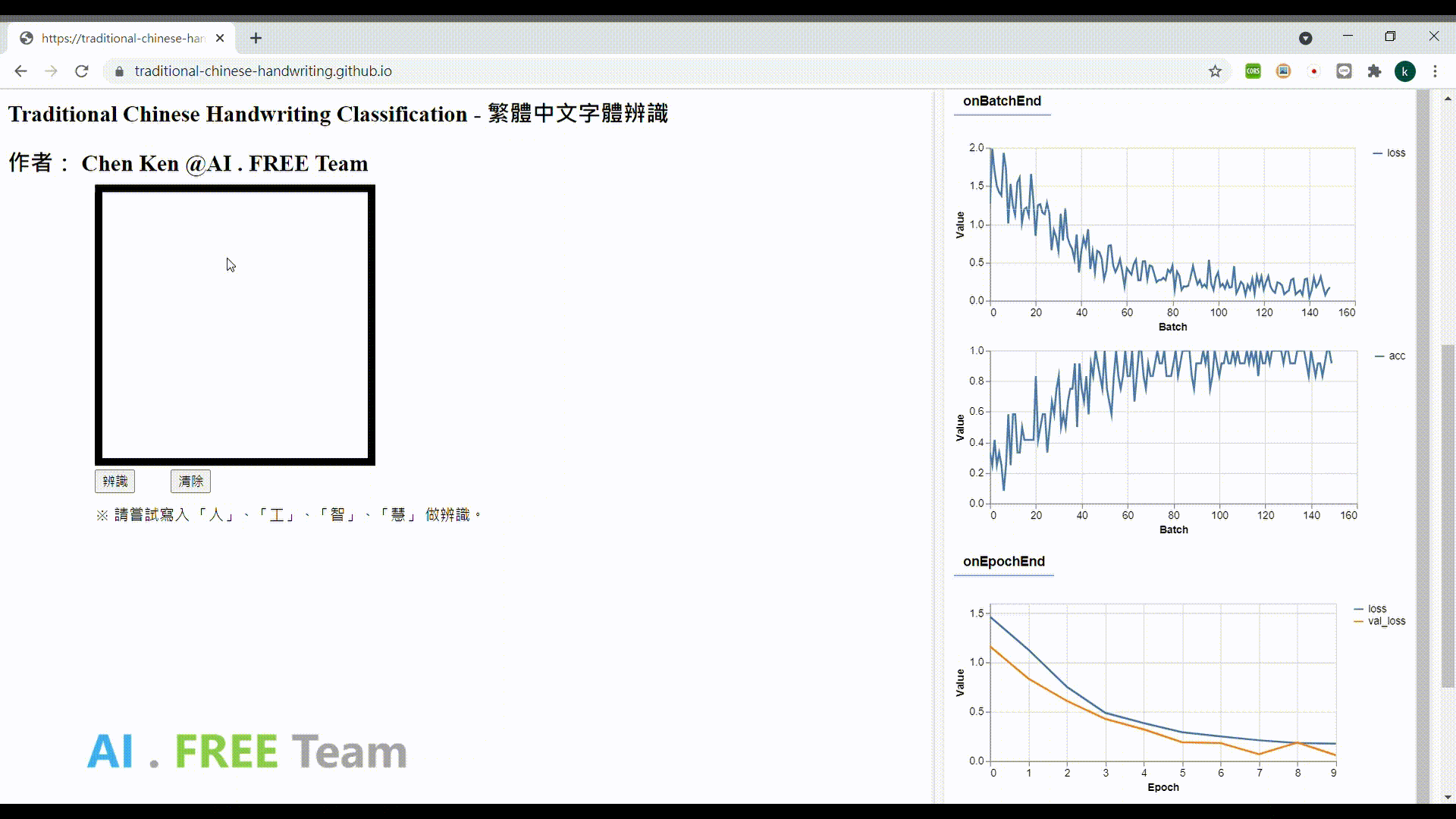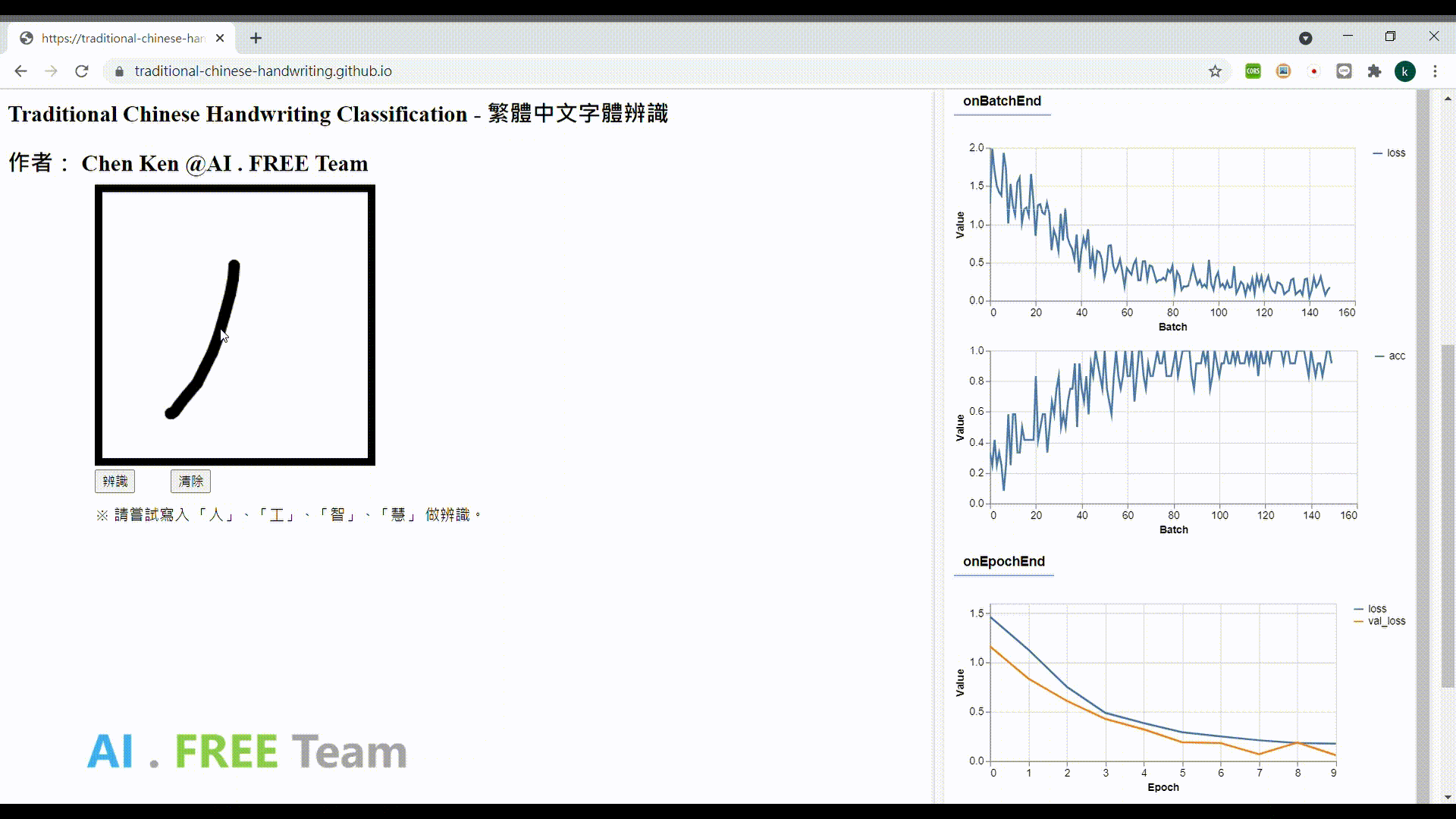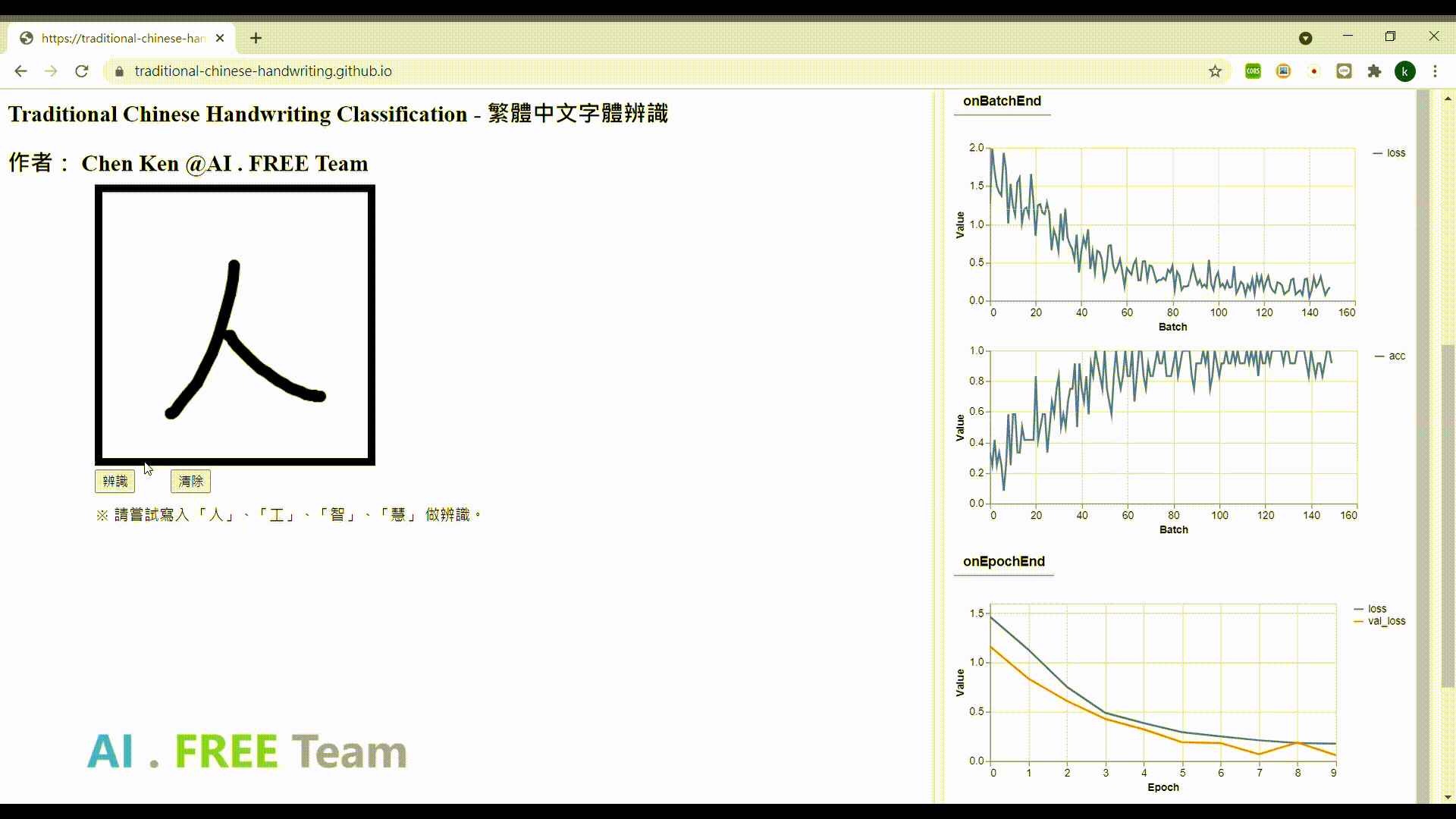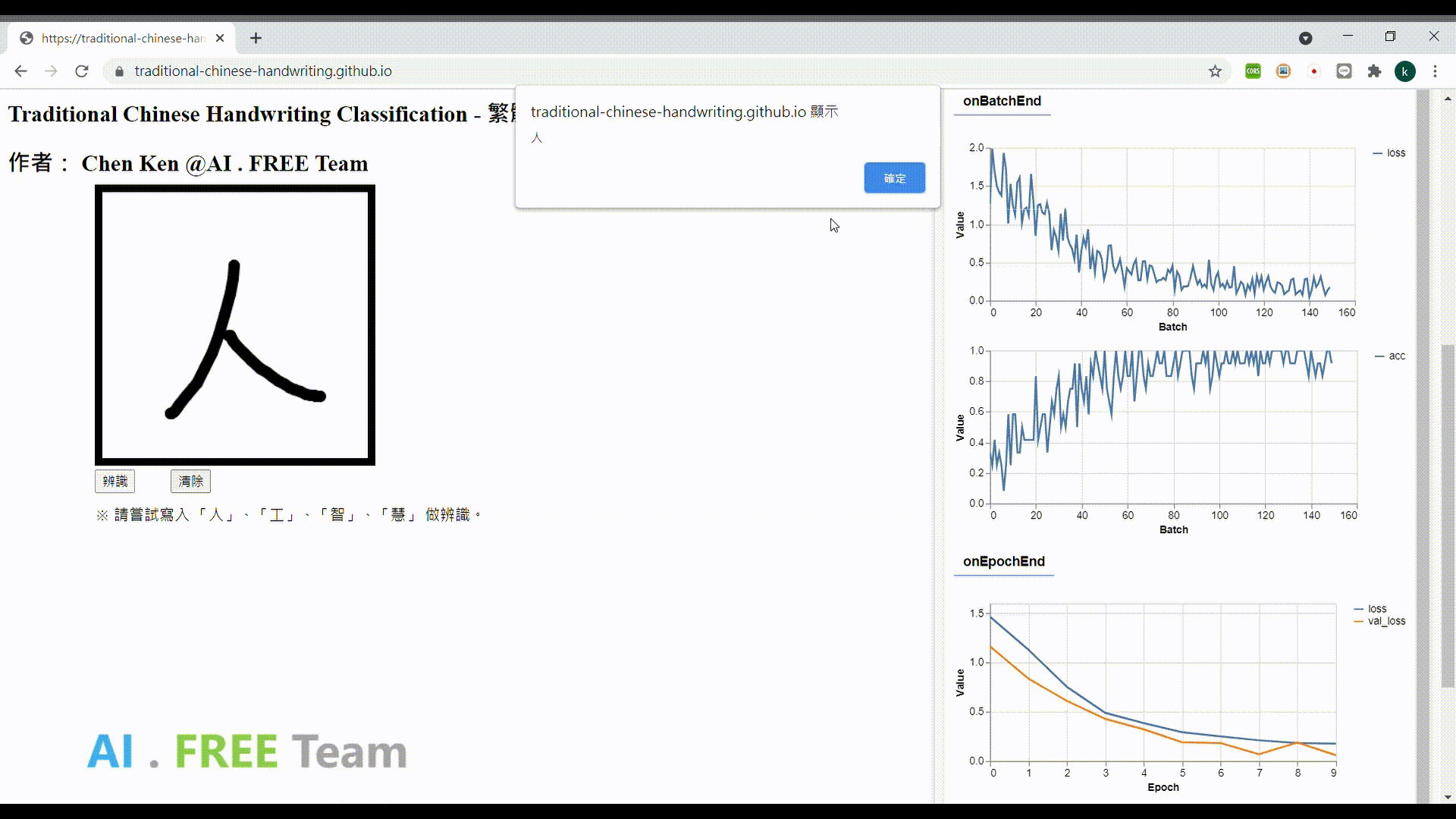
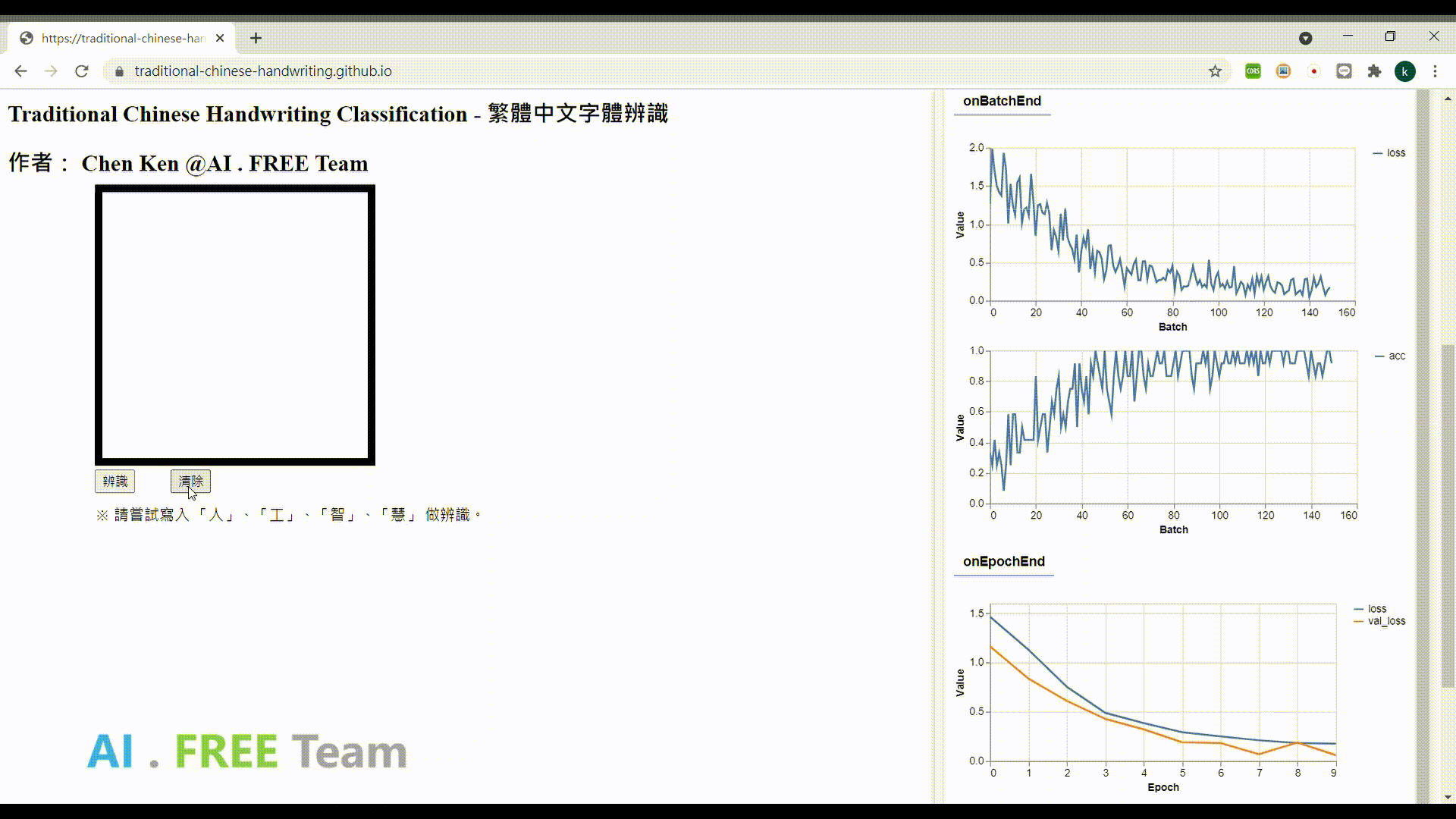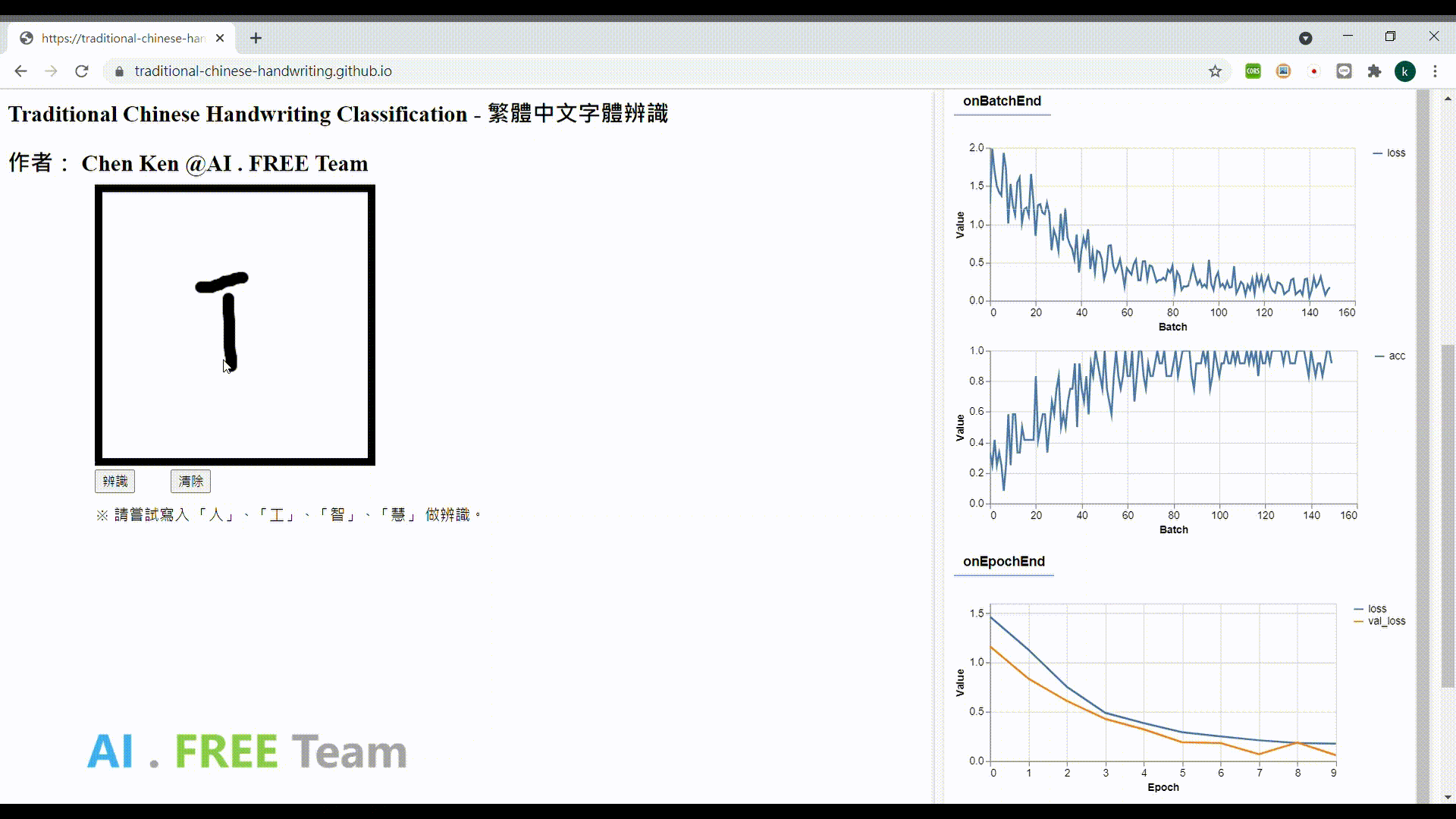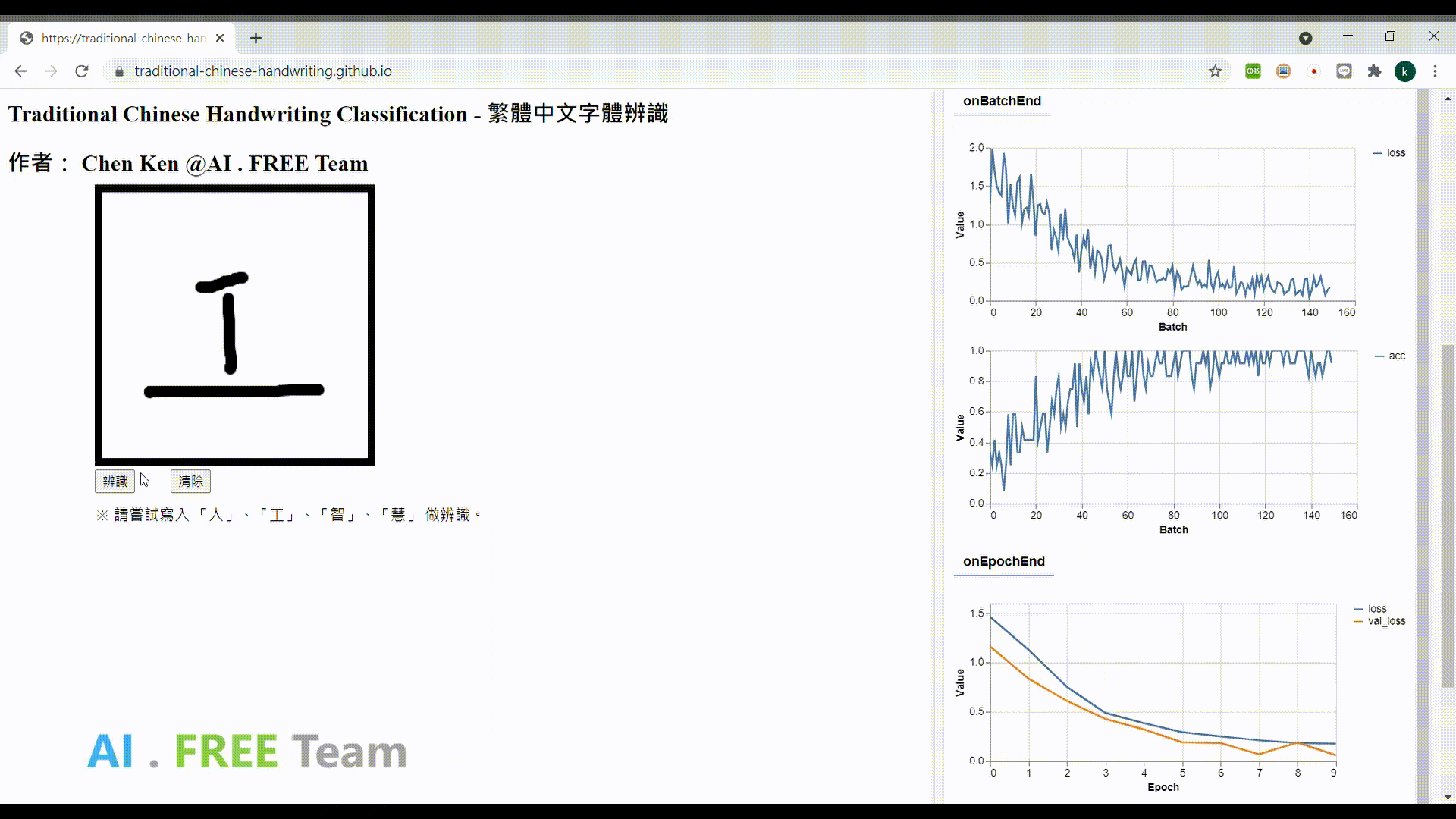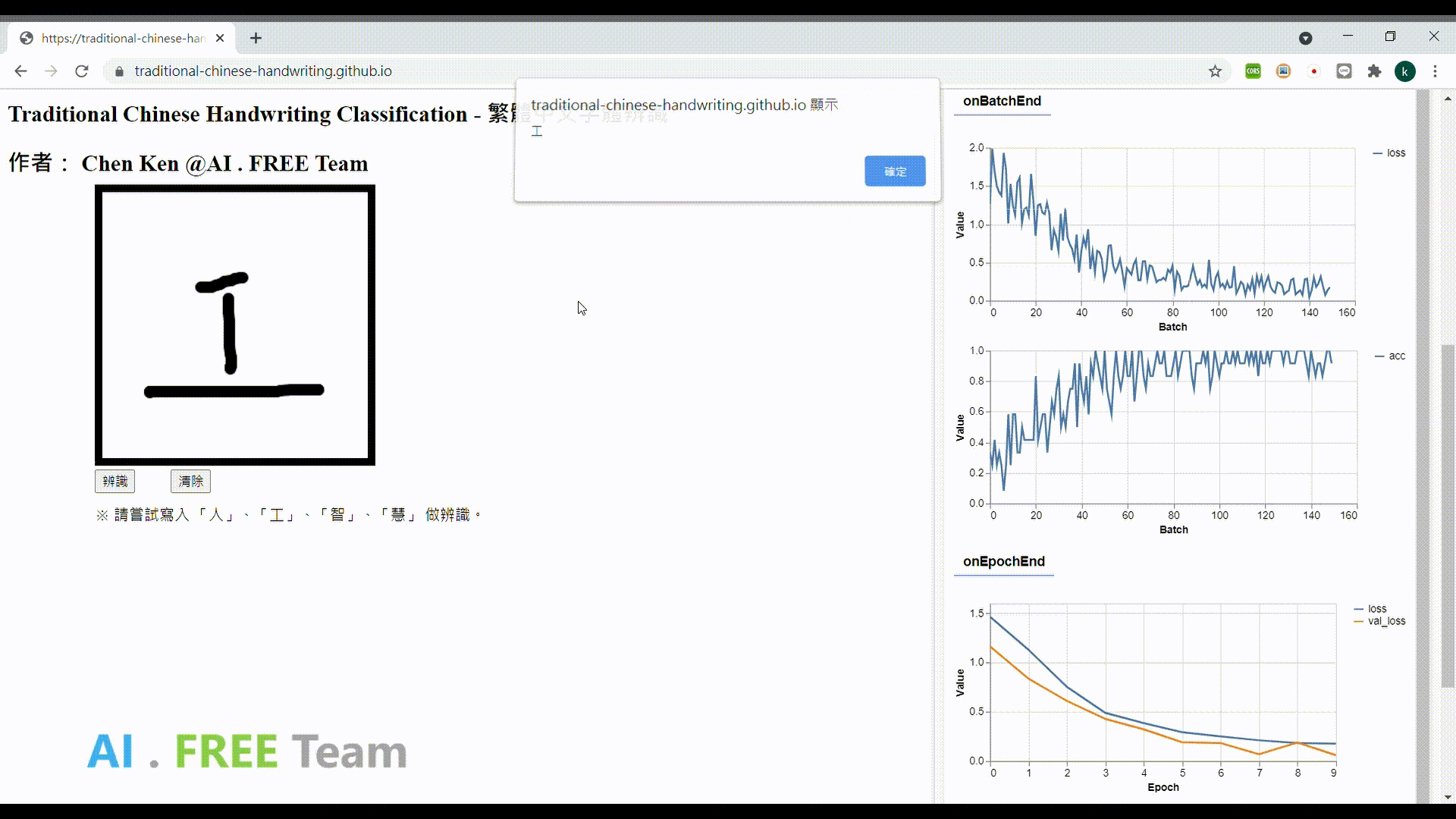
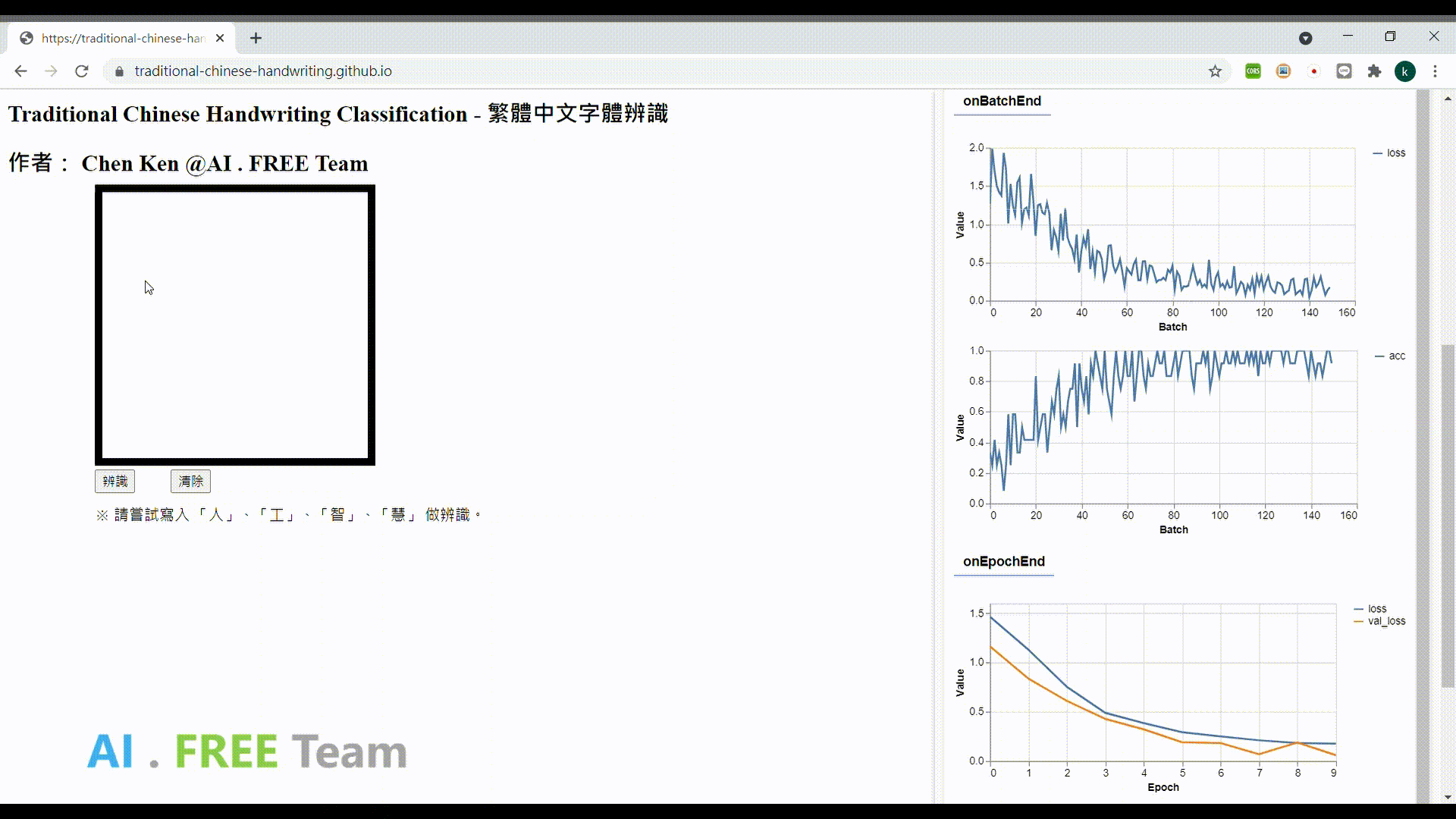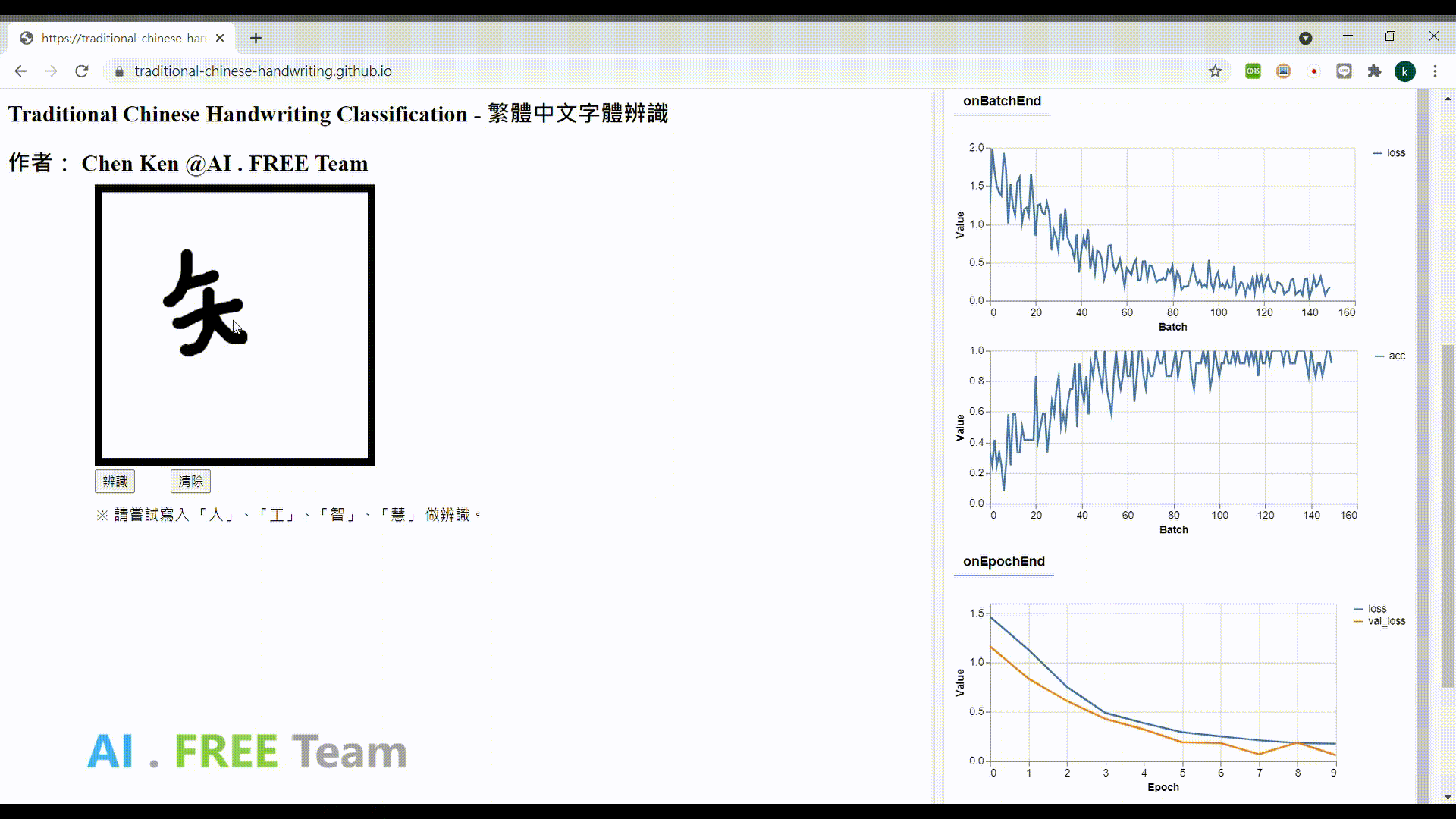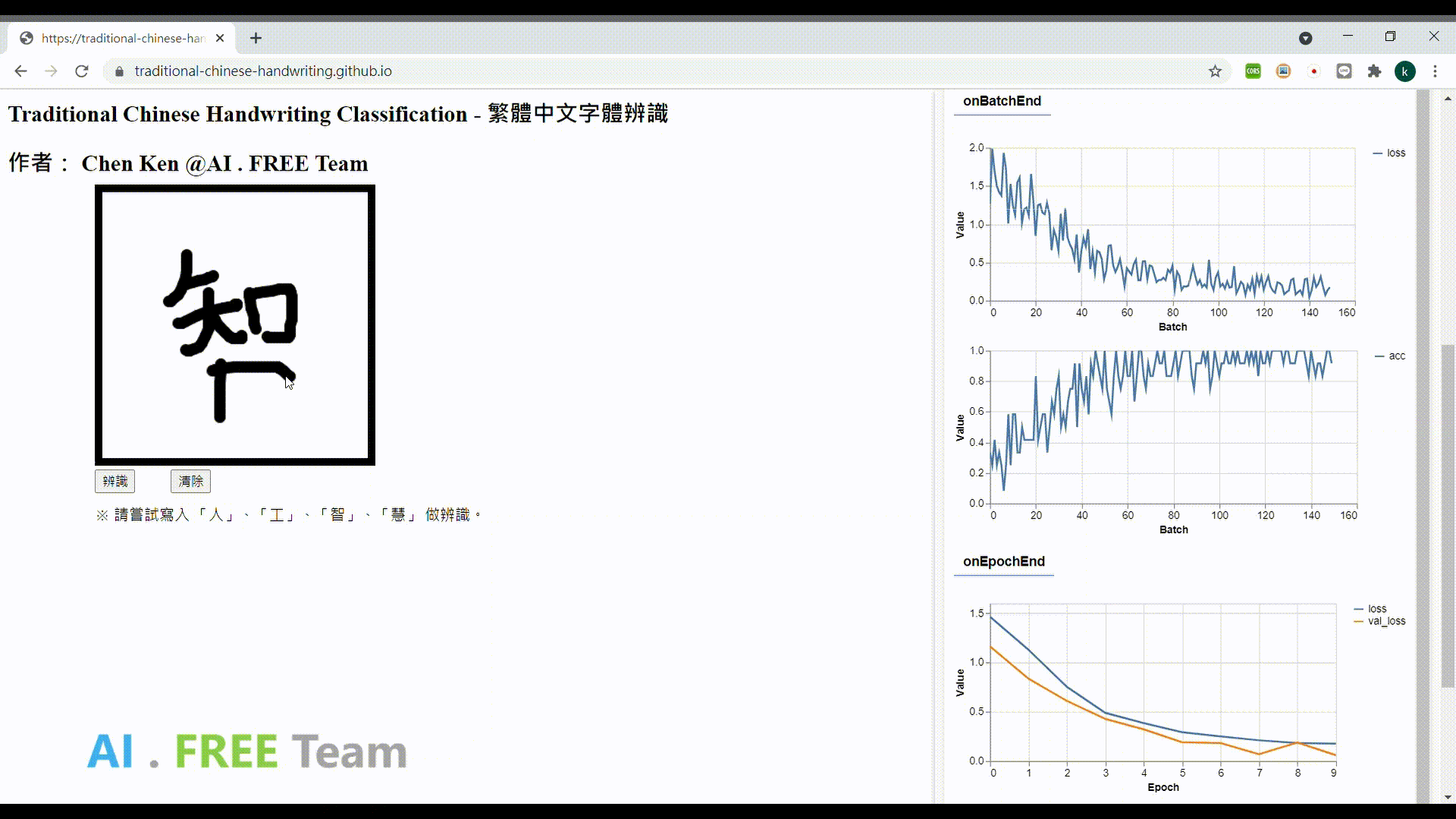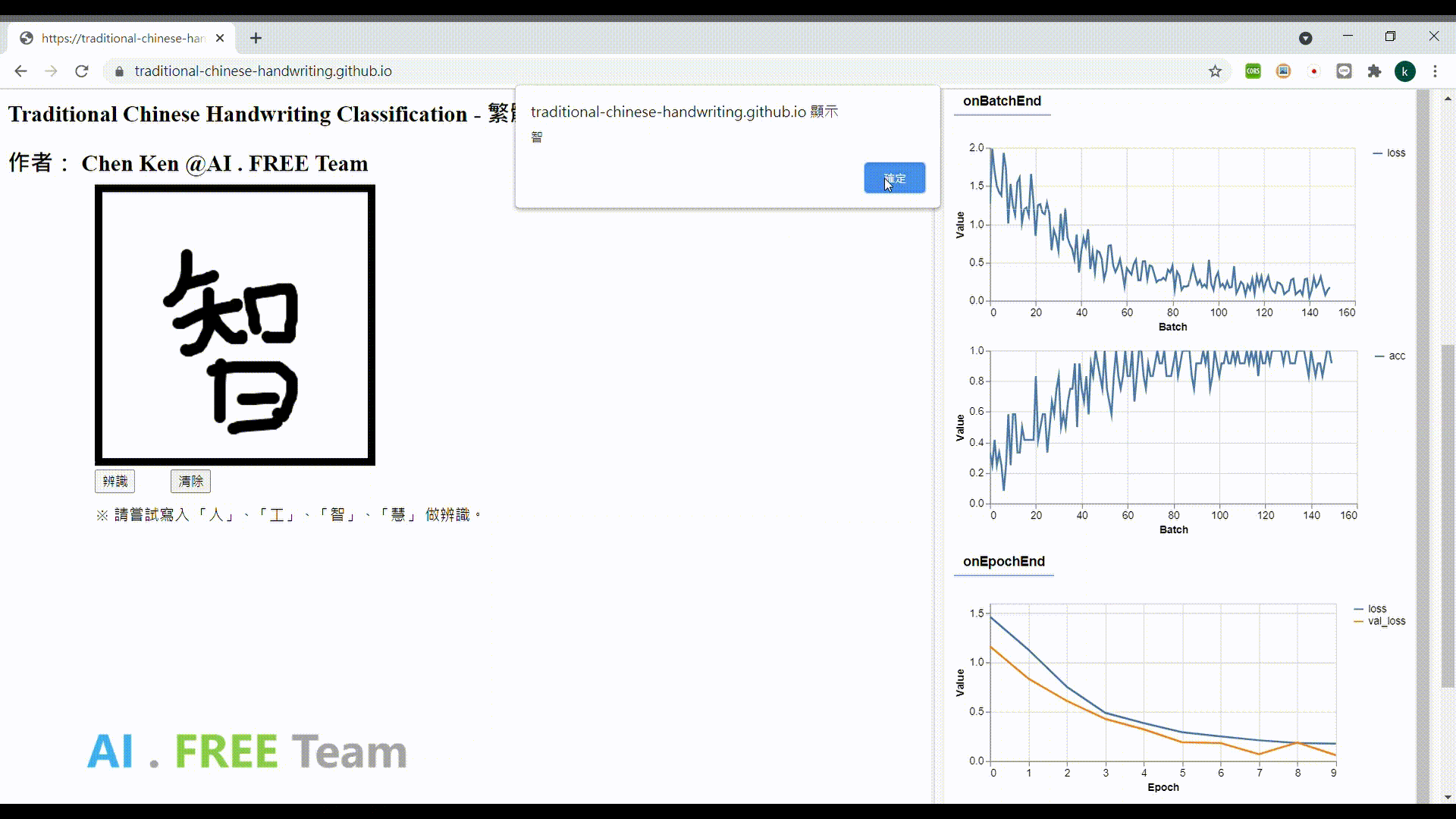
此作品為繁體中文手寫資料集之衍生應用,透過網頁瀏覽器進行 AI 模型的訓練,並即時性地視覺化呈現訓練的實際狀況,並將模型部署在網頁上,以作為使用者手寫字體辨識用。
※使用須知:每次打開此作品網頁,即會開始 training 一個新的模型,會使用到使用者電腦的運算力及電腦記憶體,訓練完成後,才能使用手寫辨識功能。 (此作品目前只 focus 電腦使用者,手機版網頁的使用暫不支持;前端開發沒花太多心思...請大家見諒)
作品連結:https://traditional-chinese-handwriting.github.io/
背景知識
本作品開發須具備以下開發知識:
1. 圖像處理的基礎知識 (RGB, np.array)
2. AI 影像辨識基礎知識 (CNN)
3. AI 開發框架知識 (Tensorflow, Keras)
4. 網頁開發基礎 (html, css, javascript)
5. Tensorflow.js API
開發素材
1. Coursera Deeplearning.ai 專業課程:Data and Deployment Specialization - Browser based Models with Tensorflow.js (第二週課程作業)
2. 繁體中文手寫資料集
3. 繁體中文手寫辨識
開發流程
1. 從資料集中抓取所需的字集
2. 將資料集轉換為 Sprite Sheet 作為網頁 training 用,準備 label Data (Sprite Sheet 介紹)
3. 修改讀取數據及模型訓練、部署的 javascript code
4. 前端修改成自己喜歡的樣子
5. Done!
專案成果
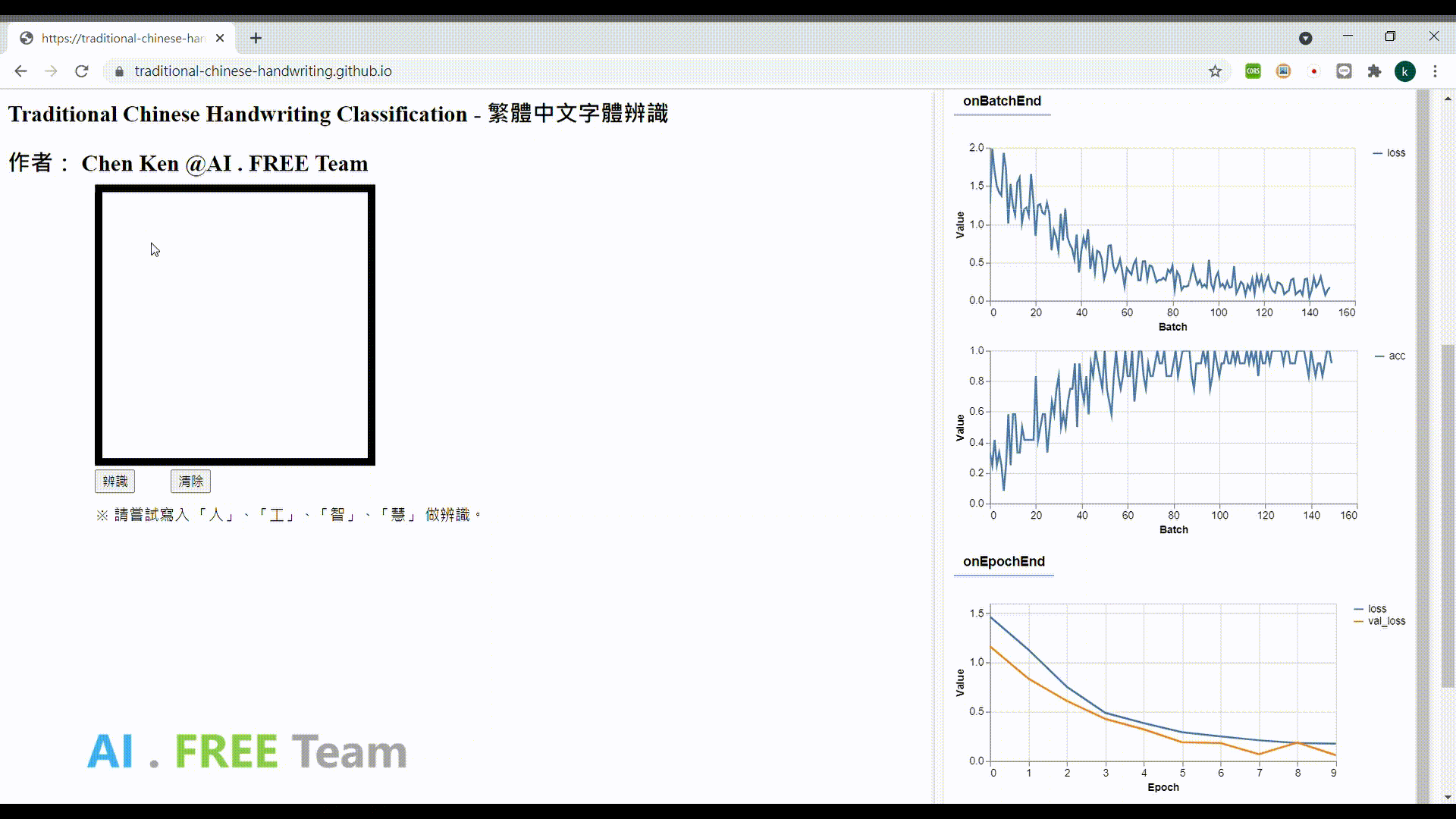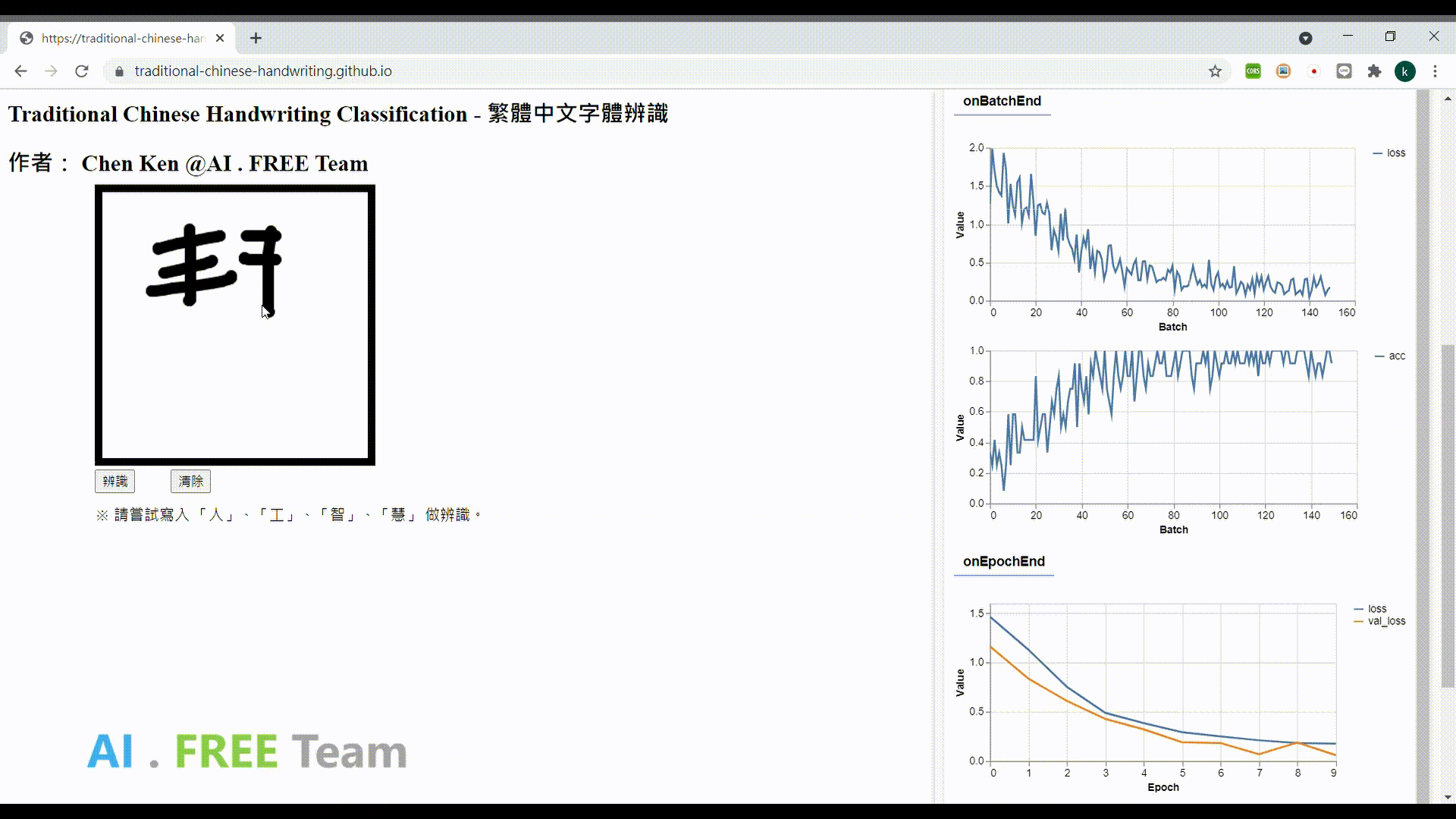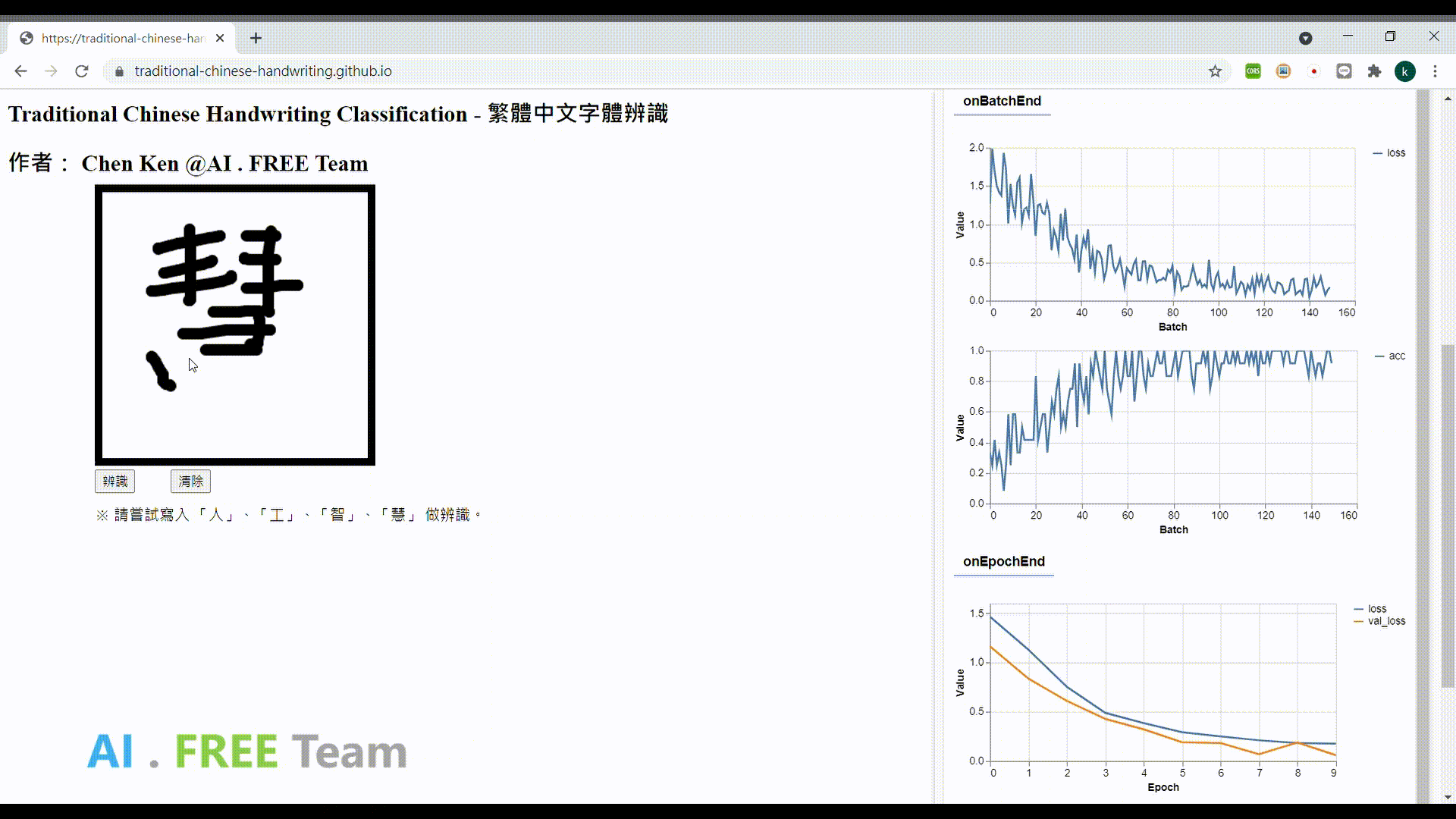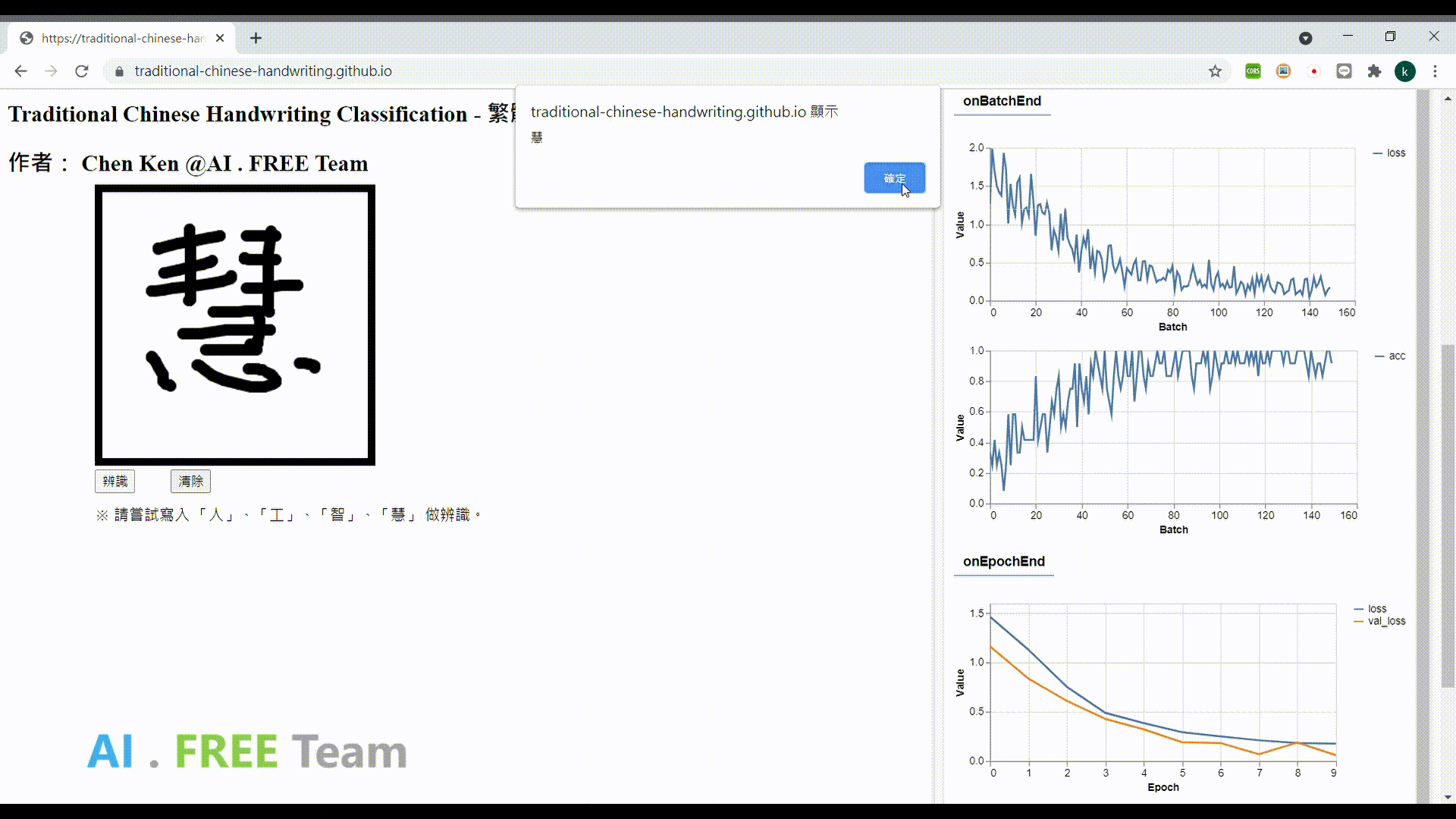
資料集授權

本資料集適用 Attribution-NonCommercial-ShareAlike 4.0 International 授權。
The dataset applied Attribution-NonCommercial-ShareAlike 4.0 International license.
※ 使用、改作、分享請附上以下資訊:
本數據集由 AI . FREE Team 改作開發自 [STUST EECS_Chinese MNIST(總集)]。如有使用、改作、分享,請註明出處及此訊息。
The dataset is AI . FREE Team development from [STUST EECS_Chinese MNIST(總集)]. If used, modified, or shared, please cite the source and the mesage.
(source: https://github.com/AI-FREE-Team/Traditional-Chinese-Handwriting-Dataset )