繁體中文手寫資料集
中文,全世界有將近十二億的使用者
在走過資料科學的路上,相信每一位學者、科學家都聽過 MNIST dataset (手寫數字資料集),或許也玩過 Fashion MNIST;身為繁體中文使用者,難免開始好奇:手寫繁體中文是否也有機會讓機器學習、神經網路成功辨識呢?讓我們一起來挑戰!
資料集說明
基於 Tegaki 開源套件下產出,總計 13,065 個不同的中文字,每一個字體平均 50 個樣本。
資料樣本
完整資料集 - 各樣本資料夾
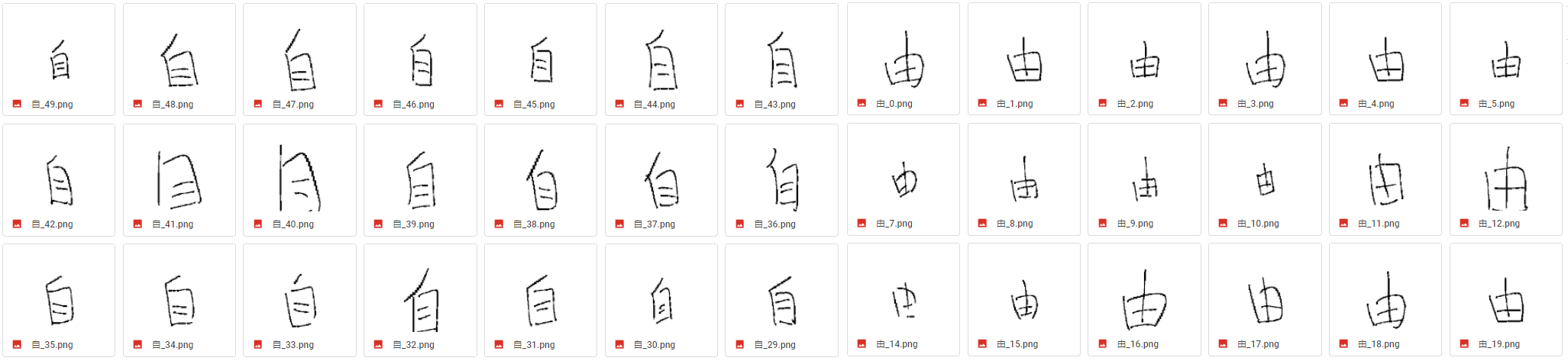
手寫"自由"範例
使用方法
git clone https://github.com/AI-FREE-Team/Traditional-Chinese-Handwriting-Dataset.git
下載完成後,解壓縮 data 資料夾內的四個檔案,共計 250,712 個圖片。
資料集部署操作 (感謝 Yen-Lin 博士 熱情貢獻)
問題與發現
資料集因壓縮至 50x50 Pixels,發現部分圖片檔筆畫不清楚、出現重疊現象。
因資料集龐大,暫時先推出常用中文字手寫資料集,完整資料集請鎖定Github專案。
資料集授權

本資料集適用 Attribution-NonCommercial-ShareAlike 4.0 International 授權。
The dataset applied Attribution-NonCommercial-ShareAlike 4.0 International license.
※ 使用、改作、分享請附上以下資訊:
本數據集由 AI . FREE Team 改作開發自 [STUST EECS_Chinese MNIST(總集)]。如有使用、改作、分享,請註明出處及此訊息。
The dataset is AI . FREE Team development from [STUST EECS_Chinese MNIST(總集)]. If used, modified, or shared, please cite the source and the mesage.
(source: https://github.com/AI-FREE-Team/Traditional-Chinese-Handwriting-Dataset )
引用
@misc{AI.FREE2020,
author = {Po-Chuan Chen},
title = {Traditional Chinese Handwriting Dataset},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/AI-FREE-Team/Traditional-Chinese-Handwriting-Dataset}},
}Source 資料來源
原資料集來源:https://scidm.nchc.org.tw/dataset/stusteecs_chinese_mnist
來源說明:本數據集開發修改自南臺科技大學電子系所提供之中文手寫字集。
Description: The Dataset is developed from Chinese handwriting data set, which is provided by Dept. EECS, Southern Taiwan University of Science and Technology.