深度學習 - 學習筆記(一)
本學習筆記課程為 Coursera DeepLearning.ai 推出之深度學習專項課程,學習筆記摘要自 AI . FREE Team 讀書會,透過學習筆記讓讀者認識深度學習。(進度:Course 1/Week 1)

一、線上課程資訊
課程名稱:深度學習專項課程 (Deep Learning Specialization)
課程教授:吳恩達 教授 (Andrew Ng)
課程主題:類神經網絡與深度學習 (Neural Network and Deep Learning)
二、課程內容
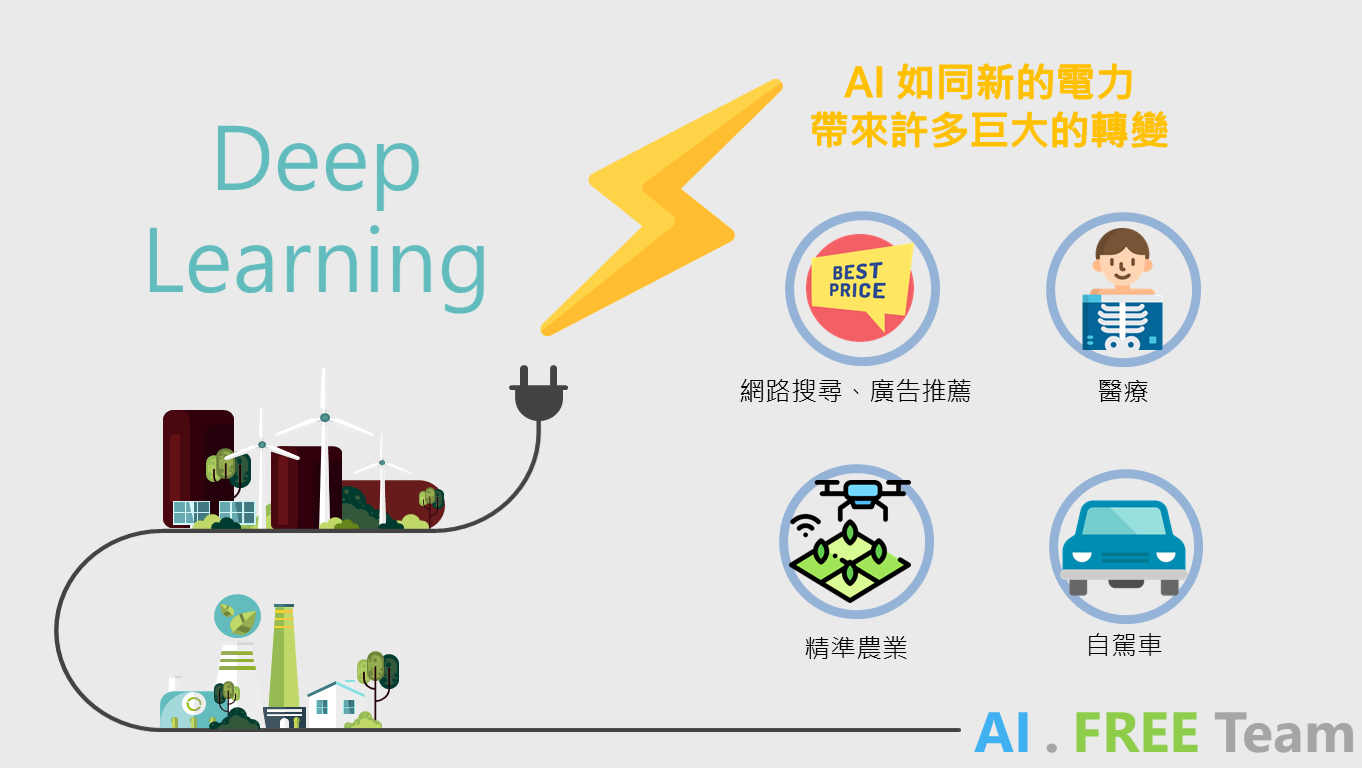
深度學習被許多學者、科技龍頭比擬做未來時代的「電力」,其應用領域相當廣泛,更緊密地與大家的日常生活息息相關。
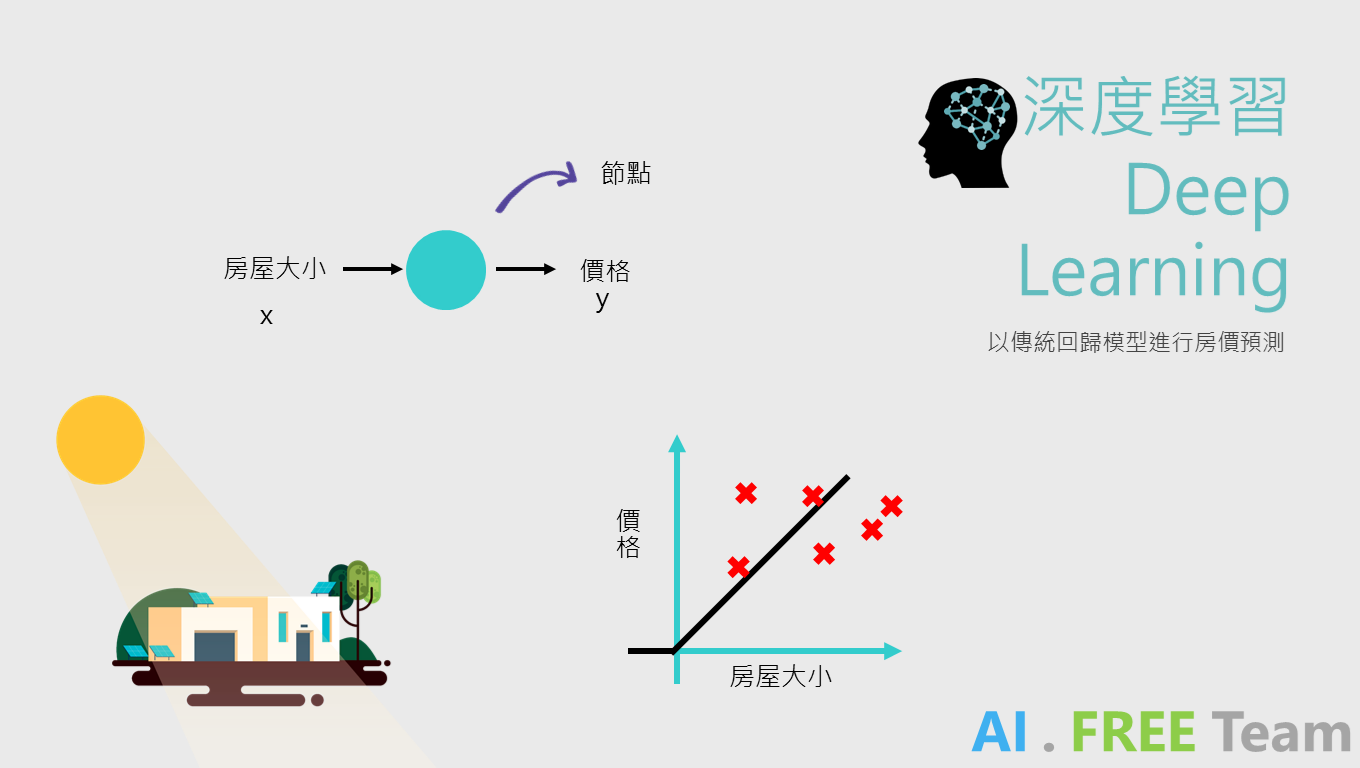
在認識深度學習以前,先讓我們以傳統的回歸模型進行房價的預測,假設房價與房屋大小呈線性關係(以Relu函數作為範例),輸入X (input) - 房屋大小,輸出Y (output) - 房價,便能透過簡單的數學運算粗估房價,例如:
參數:X - 房屋大小(坪數)、Y - 房價(單位:萬元NTD)
回歸模型:W * X + b = Y (W為權重,可想像成每坪單價;b 為偏誤,可想像成車位)
一個30坪(X)的公寓,單價30萬(W),搭配一個200萬的車位,總價粗估為1,100萬。
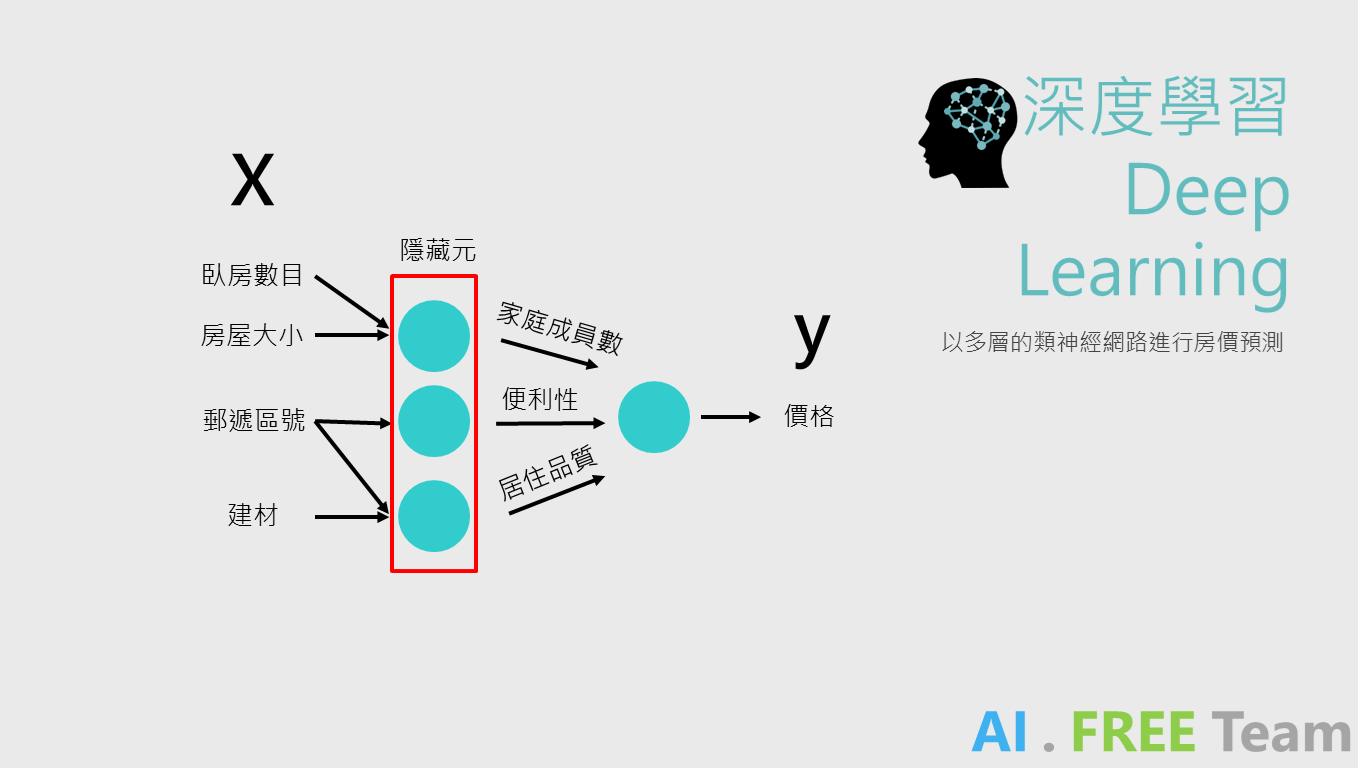
今天我們若以「類神經模型」,來進行預測房價的話,輸入的參數可以有多個參數,每一個箭頭我們可以稱之為「神經元(Neuron)」,而中間紅色框框的部分我們稱做「隱藏層(Hidden Layer)」(輸入 X 稱作「輸入層」;輸出 Y 則稱作「輸出層」),多個參數間的關係,也能透過隱藏層繁複的計算,算出可能的關聯性(如上圖所示);但在實際類神經網絡的計算中,中間的隱藏層往往即為「黑盒子」,我們無從得知神經網絡計算的邏輯為何。
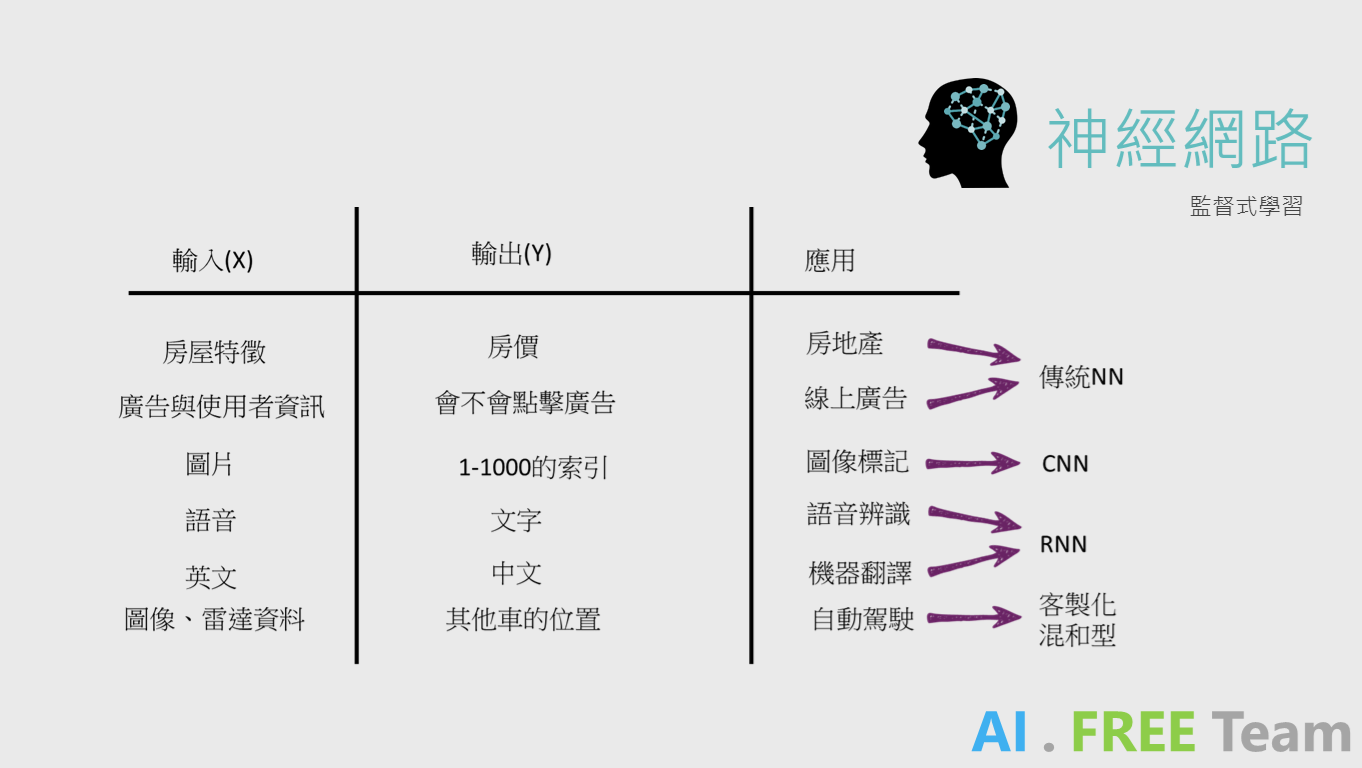
何謂監督式學習/非監督式學習呢?其最大的差異點是有沒有 Y 的存在,在資料科學中,我們稱 Y 為標籤(Label);在有標籤的資料中,我們可以透過監督式學習進行分類、回歸等任務,但是透過非監督式學習,我們僅能作分群的用途。(針對監督式學習/非監督式學習的舉例說明,歡迎參考【機器學習】 - 初識機器學習一文。)

結構化資料與非結構化資料最大的差異在於呈現的型態;結構化資料最常見的型態即為Excel 資料表、SQL 關聯式資料庫等,而非結構化資料則比比皆是,如文字檔案、圖像檔案、影音檔案;雖然深度學習模型皆能使用兩種資料,但在非結構化的資料前處理會需要多一個步驟將非結構化資料轉換成數據矩陣。(有關資料型態與資料處理的細化內容,歡迎參考【資料科學】 - 資料預先處理一文。)
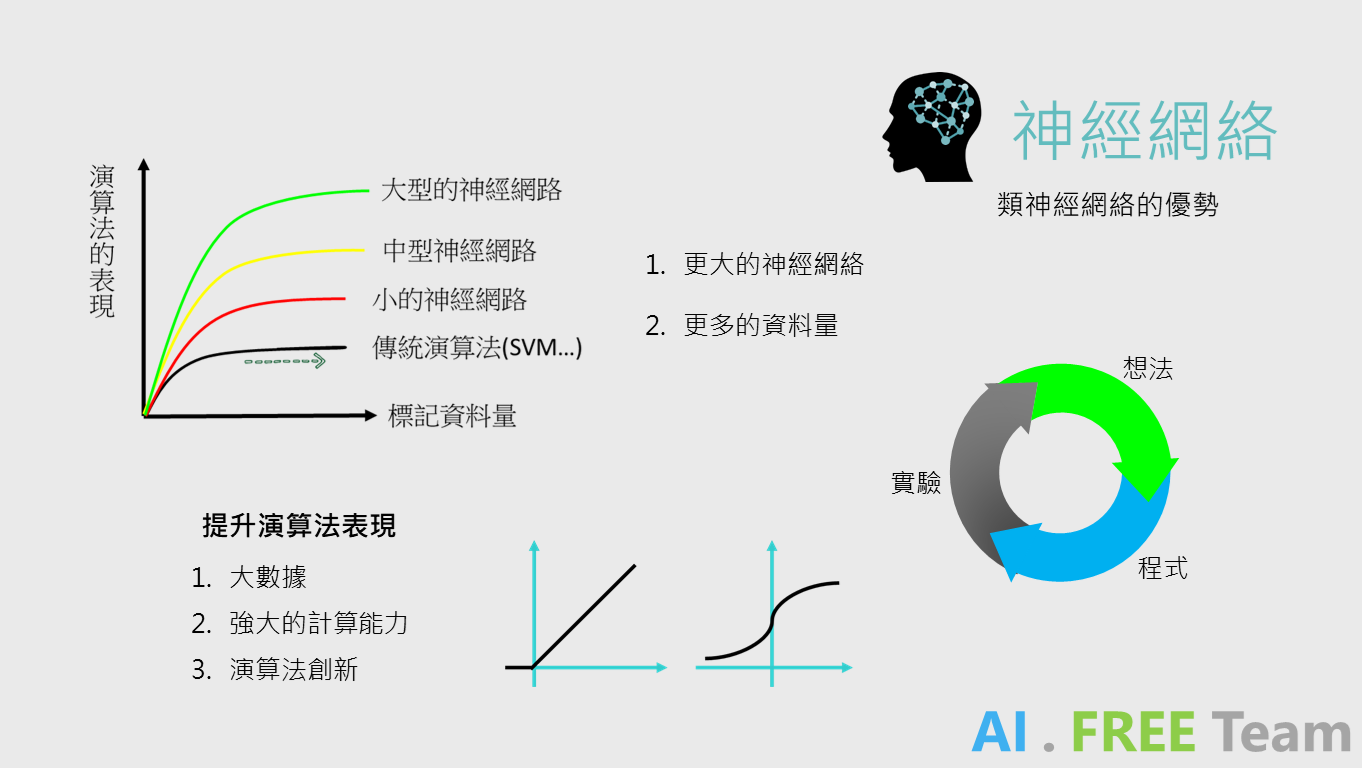
隨著硬體技術能力的提升,運算速度提升、資料的儲存成本下降,也造就類神經網路的崛起;在大數據的支持下,類神經網路的表現超越許多傳統機器學習的模型,甚至是透過更大規模的深度學習模型(更多隱藏層)、創新的演算法,更能發現模型效度大幅提升;也因為軟硬體科技的進步,更能使資料科學家加速從想法、程式撰寫到實驗結果驗證等流程。
以上統整自人工智慧自由團隊 - 深度學習專項課程讀書會,歡迎未來有興趣一起參與學習的朋友們,一起追蹤我們粉絲專頁、加入學習社團,並持續關注 AI . FREE Team 部落格,如有進一步問題或是交流需求,歡迎透過粉專 or email 聯絡我們喔!(AI.Free.Team@gmail.com)
相關資訊:
認識自由團隊:https://goo.gl/D2in5A
加入學習社群:https://goo.gl/k98CBy
企業合作專區:https://goo.gl/osGHhK
自由學習平台:https://goo.gl/ALVKKF
【AI.Free Team 介紹影片】
https://www.youtube.com/watch?v=nEOi9qk35KA