槓學習 – 零基礎成為 AI 解夢大師秘笈
本文作者:Ken
系列文章簡介
自由團隊將從0到1 手把手教各位讀者學會(1)Python基礎語法、(2)Python Web 網頁開發框架 – Django 、(3)Python網頁爬蟲 – 周易解夢網、(4)Tensorflow AI語言模型基礎與訓練 – LSTM、(5)實際部屬AI解夢模型到Web框架上。
學習資源
AI . FREE Team 讀者專屬福利 → Python Basics 免費學習資源
教學開始
終於到了成為解夢大師的最後一天,相信讀者們都已經站穩腳步、蹲好馬步,準備開始在江湖上替人解夢改運了吧!本日的教學文章將引導讀者們將開發完成的解夢模型,實際架設到Django上,提供使用者能夠透過網頁介面,進行解夢。
基礎必備知識
Python基礎程式開發
Django網頁開發框架
Python網路爬蟲
Tensorflow - AI語言模型開發(LSTM)
(若尚未熟悉其中任一技術的讀者,歡迎查看自由團隊的對應教學文章!)
為了提升讀者們的開發速度,自由團隊將提供「colab實作程式碼教學」及「Django網頁聊天機器人模板」,透過colab修改聊天機器人的Django模板,部屬LSTM模型。
基礎前置設定
Step 1.
使用 google drive,以利讀取已儲存的模型、tokenizer…等部署資訊。(若在本地端進行部署,此步驟可略。)
# 連結至個人 Google Drive
from google.colab import drive
drive.mount('/content/drive')Step 2.
下載並解壓縮自由團隊開發的開源Django聊天機器人模板。(若使用自己開發的Django APP,此步驟可略。)
# Git 下載自由團隊-開源 Django 聊天機器人模板 !git clone https://github.com/chenkenanalytic/pro_file.git # 解壓縮自由團隊-開源 Django 聊天機器人模板 壓縮檔 !7z x /content/pro_file/aifreeteam_c.7z
※ 解壓密碼,請洽 AI . FREE Team 粉絲頁,按讚、私訊:「我想要聊天機器人模板」,就免費提供給讀者解壓密碼喔!
Step 3.
下載並安裝聊天機器人套件,測試模板是否能正常運作,若想直接開發AI模型部署,此步驟可略。
# 安裝聊天機器人相關套件 !pip install chatterbot==0.8.7 !pip install chatterbot-corpus==1.1.2 # Make migration - 確保開源 Django 專案順利運作 !python /content/aifreeteam_chatbot/manage.py migrate !python /content/aifreeteam_chatbot/manage.py makemigrations
※ 注意若有出現紅色 Warnings 提醒字眼,記得點擊"RESTART RUNTIME",確保環境套件正常運行。
Step 4.
下載Ngrok並解壓縮 (便於後續我們能跨網域Access colab 的 server)
!wget https://bin.equinox.io/c/4VmDzA7iaHb/ngrok-stable-linux-amd64.zip !unzip ngrok-stable-linux-amd64.zip
Step 5.
透過Ngrok先啟動對外跨網域連線的port網址,並開啟Django網頁。
# 使用 Django 套件語法,開啟並運行 colab Localhost
# 最後透過 Ngrok 套件對公開網域開啟 Access 的權限
get_ipython().system_raw('./ngrok http 8050 &')
import timetime.sleep(1)
!curl -s http://localhost:4040/api/tunnels | python3 -c \ "import sys, json; print(json.load(sys.stdin)['tunnels'][0]['public_url'])"
print("=======================================")
!python /content/aifreeteam_chatbot/manage.py runserver 0:8050透過點擊 Ngrok 所產生的網址,我們便能順利連上在colab本地端運行的Django 網站,也能透過模板介面與chatterbot聊天機器人互動。(如下範例所示)
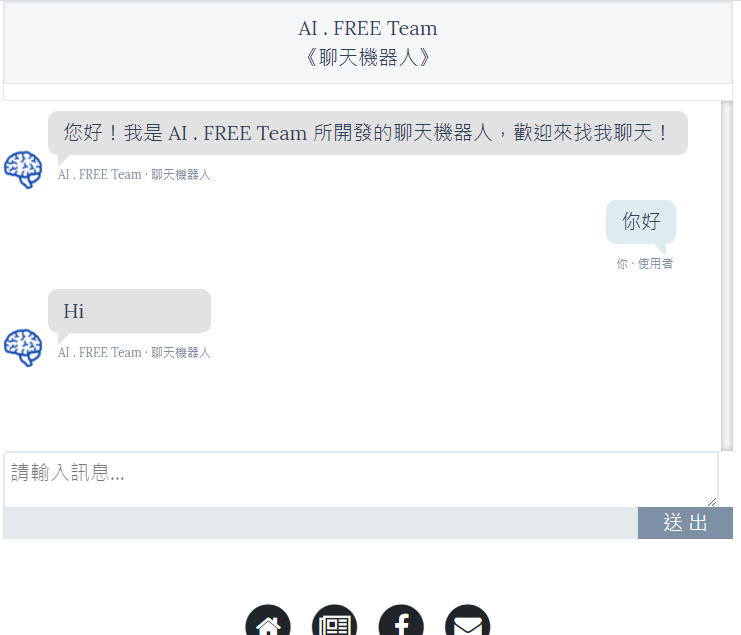
進階開發 Django 專案 – AI 模型部署
Step 6. 將 setting.py 的聊天機器人模組進行註解 or 刪除
目的是將聊天機器人的功能關閉,若不關閉,後續操作須注意不要呼叫到 chatterbot 相關套件功能,以避免開發過程額外的錯誤。
path /content/aifreeteam_chatbot/example_app/settings.py
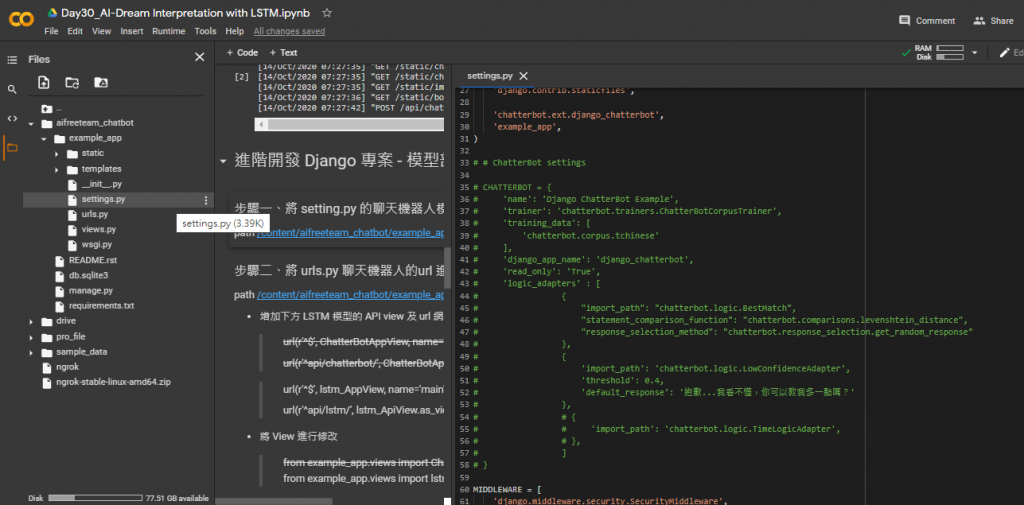
▲ 註解 chatterbot app 如上圖 (快捷鍵:選取程式碼 + ctrl + / )
Step 7. 將 urls.py 聊天機器人的url 進行註解並修改
增加LSTM 模型的 API view 及 url 網址
# url(r'^$', ChatterBotAppView, name='main'), # url(r'^api/chatterbot/', ChatterBotApiView.as_view(), name='chatterbot'), url(r'^$', lstm_AppView, name='main'), url(r'^api/lstm/', lstm_ApiView.as_view(), name='lstm')
將 View 進行修改
# 註解 chatterbot 套件(#from example_app.views import ChatterBotAppView...) # 新增 LSTM 模型 APP view 套件 from example_app.views import lstm_AppView, lstm_ApiView
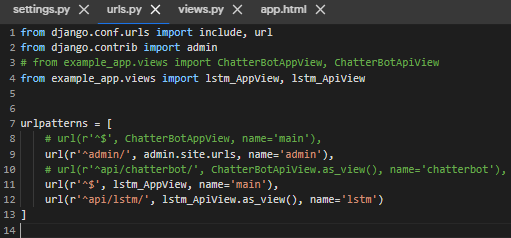
▲ 範例如上所示
Step 8. 在 Views 中,增加 LSTM 模型運行的 API view
可先在 colab 執行程式碼看看是否有 Error,
若沒有錯誤訊息,可直接於 views.py 檔案新增下述程式碼
(1) Keras 模型前置設定、文字生成函式
依據訓練 AI 模型的資訊設定參數及超參數
import tensorflow as tf import pickle # 【重要】請設定周易解夢模型資訊====================================== Tokenizer_path = '/content/drive/My Drive/LAB/IT_post/tokenizer.pickle' model_path = '/content/drive/My Drive/LAB/IT_post/model_01.h5' w = 5445 EMBEDDING_DIM = 512 UNITS = 1024 # 【重要】請設定周易解夢模型資訊======================================
讀取開發文字集的 tokenizer
# 讀取先前儲存的 Tokenizer (文字對應數字的索引) with open(Tokenizer_path, 'rb') as handle: tokenizer = pickle.load(handle)
設定模型
# 跟訓練時不同,生成過程的 BATCH_SIZE 改設為 1 BATCH_SIZE = 1 # 定義生成的模型 infer_model = tf.keras.Sequential() infer_model.add(tf.keras.layers.Embedding(input_dim=w, output_dim=EMBEDDING_DIM, batch_input_shape=[BATCH_SIZE, None])) infer_model.add(tf.keras.layers.LSTM(units=UNITS, return_sequences=True, stateful=True)) infer_model.add(tf.keras.layers.Dense(w)) # 載入已儲存模型之權重 infer_model.load_weights(model_path) infer_model.build(tf.TensorShape([1, None]))
撰寫解夢的函式 (輸入夢境內容 – dream_text、輸出 AI 解夢結果 - text_generated)
def interpret_dream(dream_text):
text_generated = dream_text
for i in range(100):
dream = tokenizer.texts_to_sequences([text_generated])[0]
# 增加 batch 維度丟入模型取得預測結果後
# 再度降維,拿掉 batch 維度
input = tf.expand_dims(dream, axis=0)
predictions = infer_model(input)
predictions = tf.squeeze(predictions, 0)
temperature = 1.0
# 利用生成溫度影響抽樣結果
predictions /= temperature
# 取得這個時間點模型生成的中文字
predicted_id = tf.random.categorical(predictions, num_samples=1)[-1,0].numpy()
input_eval = tf.expand_dims([predicted_id], 0)
partial_texts = [ tokenizer.index_word[predicted_id] ]
text_generated += partial_texts[0]
# 成功生成 解夢文字檔 → text_generated
# 透過擷取重點解夢文字作呈現
return text_generated.split('\n')[0].split('。')[0](2) API View 對接程式碼
參考 chatterbot API view 的程式碼,修改為 lstm 模型專屬的 API view。
from django.views.generic import Viewdef
lstm_AppView(request):
template_name = 'app.html'
csrf_token = get_token(request)
return render(request, 'app.html',locals())
class lstm_ApiView(View):
def get_conversation(self, request):
class Obj(object):
def __init__(self):
self.id = None
self.statements = []
conversation = Obj()
conversation.id = request.session.get('conversation_id', 0)
existing_conversation = False
def post(self, request, *args, **kwargs):
input_data = json.loads(request.read().decode('utf-8'))
if 'text' not in input_data:
return JsonResponse({'text': ['The attribute "text" is required.']}, status=400)
response = input_data
raw_text = input_data['text']
text = interpret_dream(raw_text)
text = ''.join(text).replace('##', '').strip()
response['text'] = text
response_data = response
return JsonResponse(response_data, status=200)確認以上(1) Keras 模型前置設定、文字生成函式及 (2) API View 對接程式碼,若沒有 error 產生,我們可以直接將程式碼貼到 views.py檔案中囉!
Step 9. 修改前端對應的後端函式 id
var chatterbotUrl = '{% url "lstm" %}';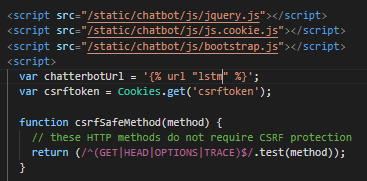
▲範例如上
Step 10. 執行 django ,開始解夢囉!
# 透過 Ngrok 套件對公開網域開啟 Access 的權限,檢視結果
get_ipython().system_raw('./ngrok http 8050 &')
import time
time.sleep(1)
!curl -s http://localhost:4040/api/tunnels | python3 -c \ "import sys, json; print(json.load(sys.stdin)['tunnels'][0]['public_url'])"
print("=======================================")
!python /content/aifreeteam_chatbot/manage.py runserver 0:8050雖然我們的網頁介面仍是聊天機器人的使用介面,但是透過對話視窗,我們便可以開始透過打字輸入進行解夢喔!
以下為幾個解夢的範例,雖然有些看起來內容感覺蠻奇異的,但是大致上 AI LSTM 模型,是有抓到解釋夢境的基礎能力。
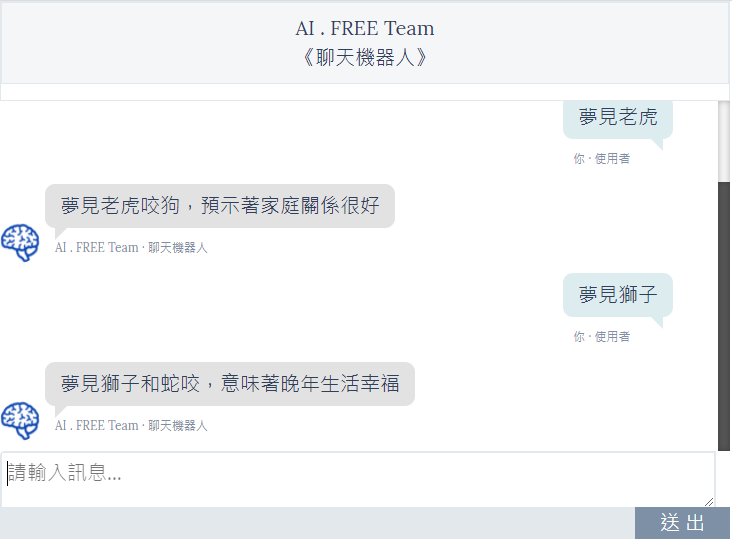

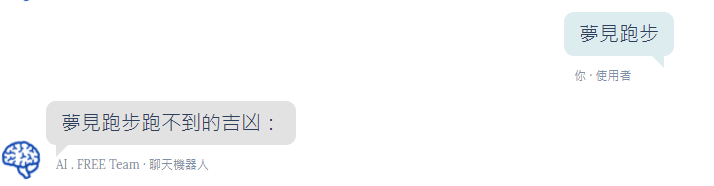
而畢竟是一個簡單的、沒有太多複雜處理、尚未優化的 AI 模型,偶爾也會出現一些比較無厘頭的解夢回覆。(如下範例)

當然我們也能夠透過修改前端網頁(html),讓介面更完整,使用起來更有感覺!
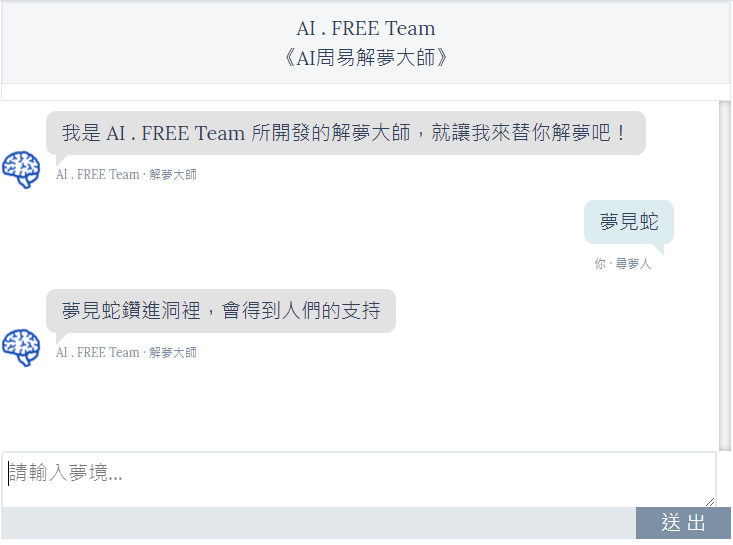
使用 colab 跟 Ngrok 工具,也能讓使用者透過手機、平板等行動設備,連線進行解夢,可說是闔家適宜的一項工具!
這一系列 AI 解夢大師的教學文章就到這邊,當然,此專案仍有許多地方可以優化、改善,例如:爬取更多資料、資料清理的環節更細緻、訓練模型更大、模型更複雜、超參數的微調… etc.
未來若有機會,我們也會針對更進一步的模型(GPT2)、資料處理的細節,進行對外開課,歡迎有興趣的讀者進一步詢問粉絲專頁!
最後還請各位讀者,敬請持續關注自由團隊粉絲專頁及加入自由團隊學習社群!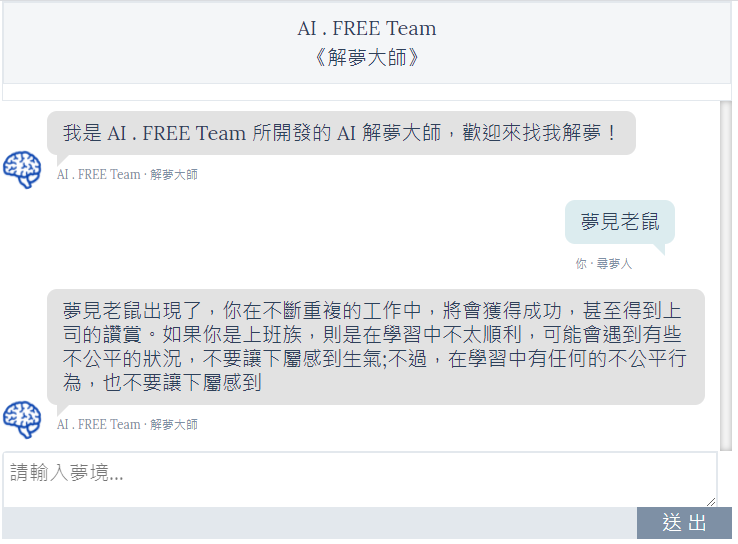
▲ 使用GPT2 訓練出來的解夢模型更完整、更全面
想更深入認識 AI . FREE Team ?
自由團隊 官方網站:https://aifreeblog.herokuapp.com/
自由團隊 Github:https://github.com/AI-FREE-Team/
自由團隊 粉絲專頁:https://www.facebook.com/AI.Free.Team/
自由團隊 IG:https://www.instagram.com/aifreeteam/
自由團隊 Youtube:https://www.youtube.com/channel/UCjw6Kuw3kwM_il39NTBJVTg/
文章同步發布於:第十二屆 IT 挑戰賽部落格